
It is very hard to get a corpus of elementary student texts to work with to explore what grammar and vocabulary beginners really can use. We have collected all the level 2 writing texts from PELIC into one file and C7 tagged it. Then put it through the ‘complexity checker’ here at EnglishGrammar.Pro and followed up with some neatening up of the code manually. I will argue that this level 2 seems to be both A1 and A2, and also show that one grammar point in the English Grammar Profile labeled as B1 grammar is picked up early by this cohort.
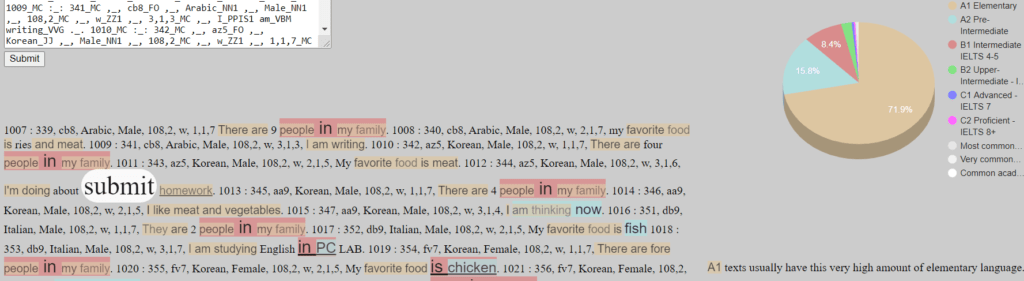
Surprisingly, the predicted level suggested for the entire corpus file as a whole is A1. Level 2 is the lowest level that the institute had at the time, so it may be more of an A1-A2 mixed level. Or the complexity checker is weaker with predictions at the low levels since we had no real specific corpus data below B1 from the Cambridge learner corpus.
However, there is obvious evidence that there are A1 students in level 2 even if the complexity checker struggles with inaccurate language:

Notice ‘cite’ is not academic vocabulary, but misspelt ‘city.’ Also, ‘mall’ has been highlighted incorrectly as higher complexity = using no article when speaking of things in general. Obviously, this should be ‘malls’. There are many highlighted vocabulary items too that make no sense such as ‘week up leat’ that should be ‘wake up late.’ The complexity checker has incorrectly assumed some kind of range of determiners related to time.
Still, with no accuracy aspect to the checker, the large number of spelling errors remain untagged as anything and do not go into the equation of predicting the level directly. They do, however, break up the strings of words that the checker is looking for as grammar structures. It is not just the complexity checker, but also the claws7 tagger that struggles to identify parts of speech when the language is inaccurate.
Then there is another problem. The vocabulary data from the English Vocabulary Profile is only what those students have used. ‘cluttered’ for example, is not in the EVP and unmarked here. (not that it was used correctly)
The final thing the complexity checker can’t do is check the meaning/usage of words that are spelt and found in accurate language. For example, the kitchen is not:
cookery: the practice or skill of preparing and cooking food.

Next, after writing the above post I decided to go through and manually unhighlight the overpredicted structures. To do this I used strikethrough code snippets < s > … < /s > or just removed the tags, and added square brackets [ ] to add in missing words. This took away errors that the complexity checker could not use to predict the level. For example, if a word was clearly not shown to be able to be used logically in a sentence, it should not be highlighted as more advanced.
For anyone that would like to see the resulting output, you can copy-paste the tagged and edited data => into the submit box clicking here:
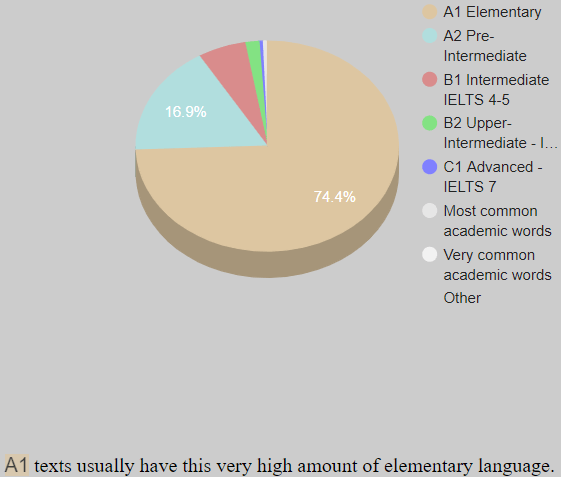
The proportions now look like the pie below with 90+% in the A levels which makes it hard to give it an overall of A2.
Here are some of the stand out sentences in level 2:
B1 grammar point by elementary students
The 5 examples we found quickly (since everything was highlighted in red) of one B1 grammar point: using a prepositional phrase after a noun phrase shows why the EGP research needs to be duplicated in other learner corpora. If we can suggest that even in just this small sample of level 2 writing which we have shown to be generally A1-A2, that students already are showing the ability to do similar things with their language that is labelled B1 by EGP, there may be some questions about the EGP as a CEFR standard if further refinements will not happen.

![]()
The difference between the above PELIC examples and the B1 ones in the EGP below can be guessed at but they are not explained in the EGP description.
- It was a beautiful red dress with blue flowers on the back. (Andorra; B1 THRESHOLD; 2010; French; Pass)
- Yesterday a TV company came to our school to make a film about Bavarian pupils. (Germany; B1 THRESHOLD; 2008; German; Pass)
- I don’t spend too much time in front of the television, I just watch it twice a week and on Sundays morning. (Brazil; B1 THRESHOLD; 2007; Portuguese; Pass)
- I received your letter and you asked me about the future of my town. (Brazil; B1 THRESHOLD; 2007; Portuguese; Pass)
- I have to travel to Montevideo to see my doctor because I’m having some problems with my health. (Uruguay; B1 THRESHOLD; 2009; Spanish – Latin American; Pass)
Another example of the above grammar is masked by ‘on display’ which demonstrates the B2 language point of using no article. The sentence (which has been corrected for errors) is the most suspicious line of text in the level 2 writing easily noticed as C2 overall.
52205 : 17175, ai3, Chinese,, 324,2, w, 2373,1,17
He has many painting[s] and sculpture[s] on display, and his artistic productions are popular from [for] many people.

Here is another example of using no article correctly:
1020 : 355, fv7, Korean, Female, 108,2, w, 2,1,5
My favorite food is chicken.
VOCABULARY?
Here is a list of advanced words with full-stops between each.
1363 : 511, di1, Chinese, FeM, 108, 55,1,11 Describe yourself. Write one sentence. Use two adjectives in your sentence.
My personality is calm. talkative. easy-going. and a little careless.
![]()
If we consider the proportions of just this one sentence:
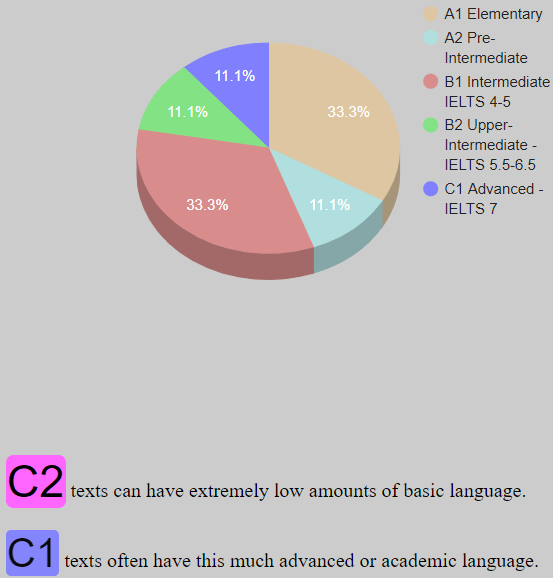
We can assume this was not written under exam like / invigilated conditions. And the other thing that comes to mind is that 1 example of a word in such a small corpus is not enough to be able to say that students at Level 2 can use this vocabulary. Even if we look at words that appear 4 times and not worrying about versions there is only 1 b1 item ‘neat’.
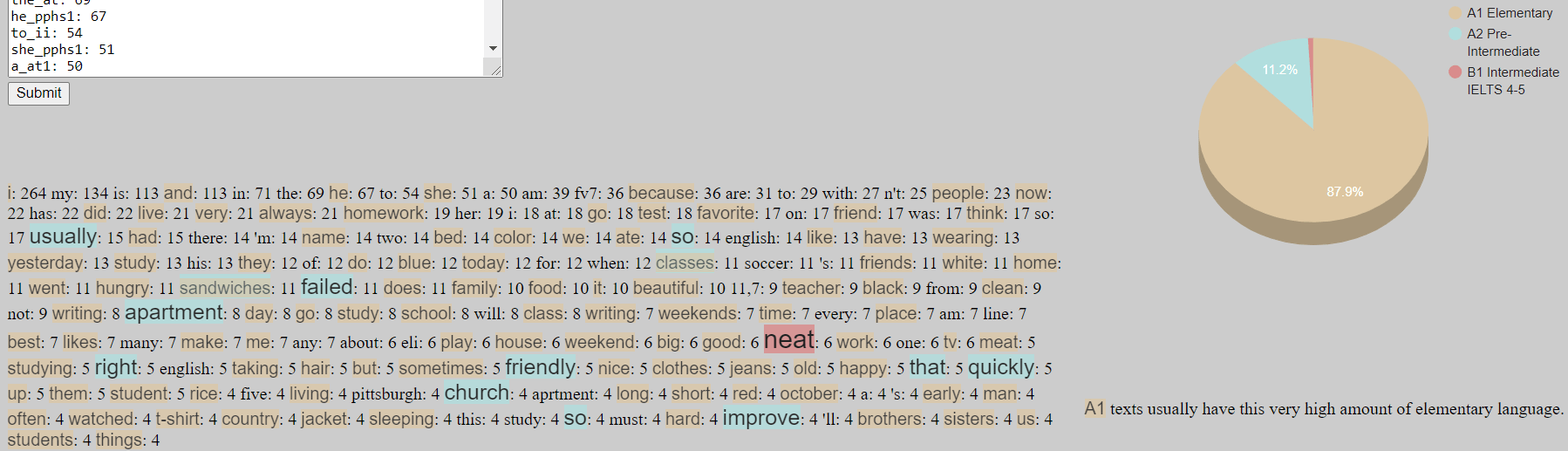
A quick look at ‘neat’ through Antconc:

I am not sure about ‘neat temperament’ but with this many examples I feel confident ‘neat’ can be used well by Level 2 students. I double checked that ‘neat’ is indeed in EVP at B1: ![]()
TASK EFFECT:
The complexity checker’s use of highlighting with colour and size makes it fast to spot repetitions of specific tasks. Here ‘I was hungry, so I ate 2 sandwiches’ can be seen to be written out by many different students. This controlled task does not really provide evidence that the students can choose to use the B2 grammar point. PAST simple with a range of subordinating conjunctions
171 Write ONE sentence that connects the two sentences. Use “so” to connect the sentences.
I ate two sandwiches.
I was so hungry.

B2 grammar?
Sadly though I am not exactly sure what the task was. It seems to be about writing about students or teachers in the class based on prompts. There is no mention in the questions.csv that they were required to use complex sentences, but it seems highly likely.


In the section toward the end of the corpus, we spot a great variety of complex sentences and guess there is task effect built-in but the sheer variety is convincing. It is not only rewarding to see such a variety of complexity but seeing the same types of conjunctions repeated in different colours highlights the enormous task the EGP has undertaken in differentiating proficiency through language. For example, when certain conjunctions are followed by the past tense, it suggests upper-intermediate proficiency and pre-intermediate when they are followed by the present tense.
Yet before we can claim that with this many examples that the EGP might have gotten the grammar point wrong, let’s look much closer at the sentences. We quickly realise almost all of the examples come from the same student, and most of the sentences have errors with verbs. For both of these reasons we cannot say that level 2 students can use this B2 grammar point well:
23420 : 5200, bm6, Arabic, M, 167, 648,1,10, When I went to Chicago, I bought a nice coat.
Korean Male ‘gz2’:
52461 : 17349, gz2, Korean, M, 324, 2371,1,12, Because when I asked
something to him[him something], he always answeredtome.52462 : 17350, gz2, Korean, M, 324, 2372,1,22, This is because she finishes her work every[ ]day. If she didn’t finish her work, she didn’t sleep
before finished work.52464 : 17352, gz2, Korean, M, 324, 2374,1,14, When I had [a] meeting with him, I was late but
he[it didn’t]doesn’tmatter.52465 : 17353, gz2, Korean, M, 324, 2375,1,24, Usually he greeted
tome when we met in class and he wants[ed] to talk with me. So, I think he is [a] friendly man.52467 : 17355, gz2, Korean, M, 324, 2377,1,26, When I visited her house, I [was] su[r]
pprised .52468 : 17356, gz2, Korean, M, 324, 2378,1,29, If he met a student in ELI, the student didn’t go back home because he catched the student for talking.
52469 : 17357, gz2, Korean, M, 324, 2379,1,36, When she was very sick, she didn’t miss her class. When her student had mid term test,
they got low score all of them[all of them got low scores,] but she didn’t [get] angry.52470 : 17358, gz2, Korean, M, 324, 2380,1,30, I think she has [a] positive outlook on her life because when I had her class, she ha[d a] smile every[ ]day.